昨日,北京大学与深度求索(DeepSeek)正式宣布联合推出并开源大模型推理加速框架DSpark,旨在破解大语言模型在高并发推理场景下因频繁前向计算导致的响应延迟与算力浪费顽疾。在标准自回归生成中,每输出一个词元都需消耗完整算力,严重制约实时响应速度。虽然推测解码是主流提速手段,但传统方案存在明显短板——串行生成耗时较长,并行模型处理长序列时候选接受率常下滑,算力无效消耗严重。
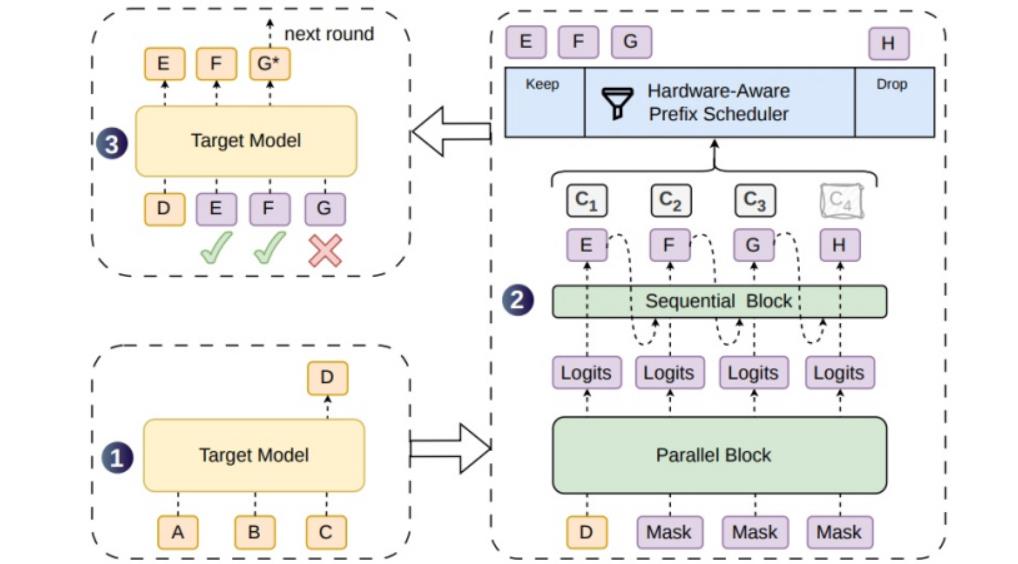
针对上述痛点,DSpark创新引入双重优化机制。在候选生成阶段,采用半自回归架构,通过并行主干网络一次性输出高质量基础特征,并辅以轻量化模块优化文本逻辑,仅需两层Transformer结构即可优于五层并行模型表现,在速度与质量间取得巧妙平衡。在验证调度层面,引入置信度调度验证机制,由硬件感知前缀调度器实时判断算力负载,优先处理高可靠性文本片段,最大限度减少无效计算。经通义千问3、Gemma4等主流模型在代码编写、数学推理及日常对话等多场景下严格测试,DSpark单轮有效生成长度明显优于Eagle3和DFlash等基线模型,尤其在长序列任务中有效缓解了候选有效率衰减难题。
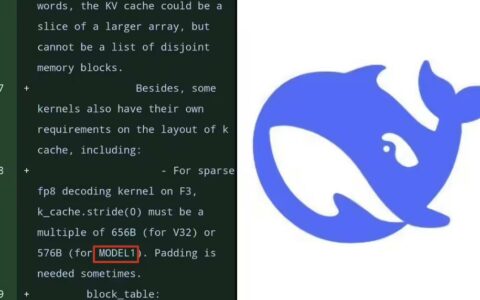
工程化方面,团队进行了深度系统级优化,包括序列打包降低内存消耗、异步调度模式消除GPU流水线卡顿,并确保对主流CUDA硬件生态的兼容。DSpark已率先落地于DeepSeek-V4-Flash与DeepSeek-V4-Pro预览版服务引擎,实测显示系统整体吞吐量实现跨越式增长。目前,深度求索已在GitHub DeepSpec项目中开源了DSpark、DFlash及Eagle3的全套训练代码、模型权重及评估工具,此举将大幅降低行业高性能推理服务部署成本,为大模型低成本普及提供切实可行的技术范式。
原创文章,作者:AI,如若转载,请注明出处:https://www.kejixun.co/article/756292.html