
据外媒TechCrunch报道,AI初创公司Stability AI近日推出全新音频生成模型家族Stability Audio 3.0,其顶级版本可生成长达六分钟以上的专业级音乐。
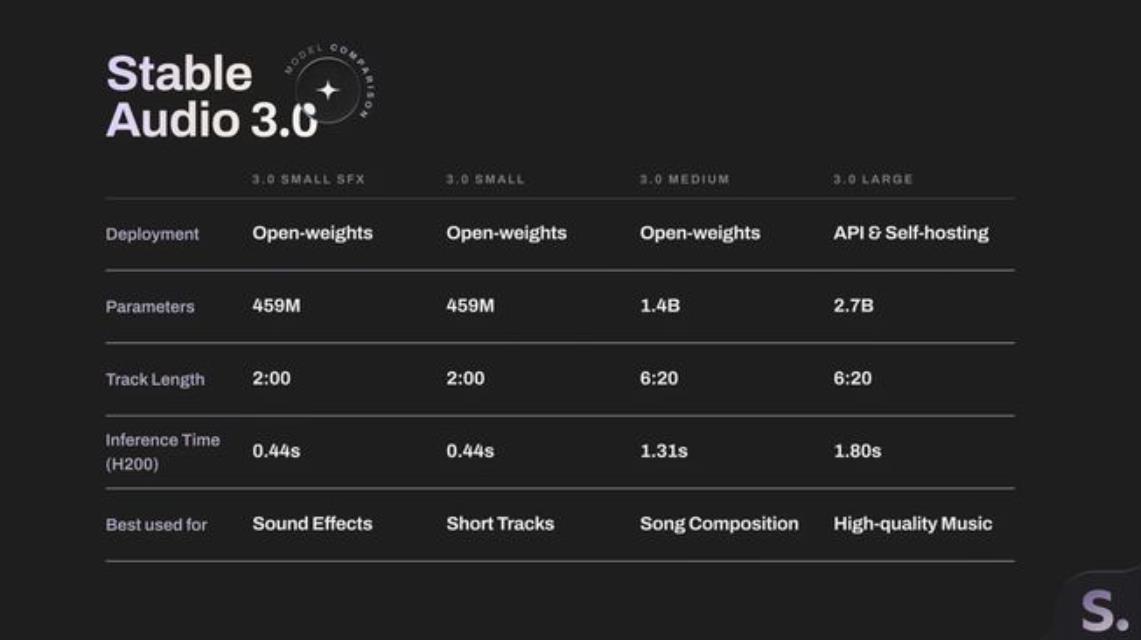
此次共推出四款不同规格的模型,分别为45900万参数的小型XFS与小型版、14亿参数的中型版以及27亿参数的大型版。两款小型模型专注于设备端运行,可本地生成两分钟以内的声音与音乐。中型和大型模型则展现出更强的架构控制力,能够创作长达6分20秒的完整乐曲,并精准维持音乐结构与旋律基调,这一长度较2024年的Stable Audio 2.0实现翻倍以上跨越。
为回馈开源社区,Stability AI已将小型SFX、小型及中型模型开源,公众可自由下载并修改权重。但最顶尖的大型模型目前仅通过API与付费托管服务提供,年营收超过100万美元的企业必须购买商业授权。为规避合规风险,Stability AI去年已同华纳音乐集团、环球音乐集团达成深度合作,强调最新音频模型全量基于合法授权的数据集训练而成。
此外,公司正紧锣密鼓为专业音乐人打造全新产品线,曾先后担任环球音频与芬达首席数字官的伊桑·卡普兰已正式加盟,负责领衔该业务。
原创文章,作者:聆听,如若转载,请注明出处:https://www.kejixun.co/article/753022.html