据外媒报道,苹果公司发布了一篇重要研究论文,详细介绍了其全新的多模态AI模型“Manzano”。该模型的最大亮点在于,能近乎无损地同时实现精准的“视觉理解”与高质量的“文本生成图像”,有望解决行业内长期存在的任务冲突难题。
传统多模态模型在同时处理图像理解与图像生成时,往往因视觉数据处理方式的内在矛盾而被迫做出性能妥协。Manzano通过创新的三段式架构攻克了这一挑战:首先,其“混合视觉分词器”能同步生成连续与离散的视觉表示;接着,大语言模型负责预测图像语义;最后,“扩散解码器”进行精细的像素级渲染。
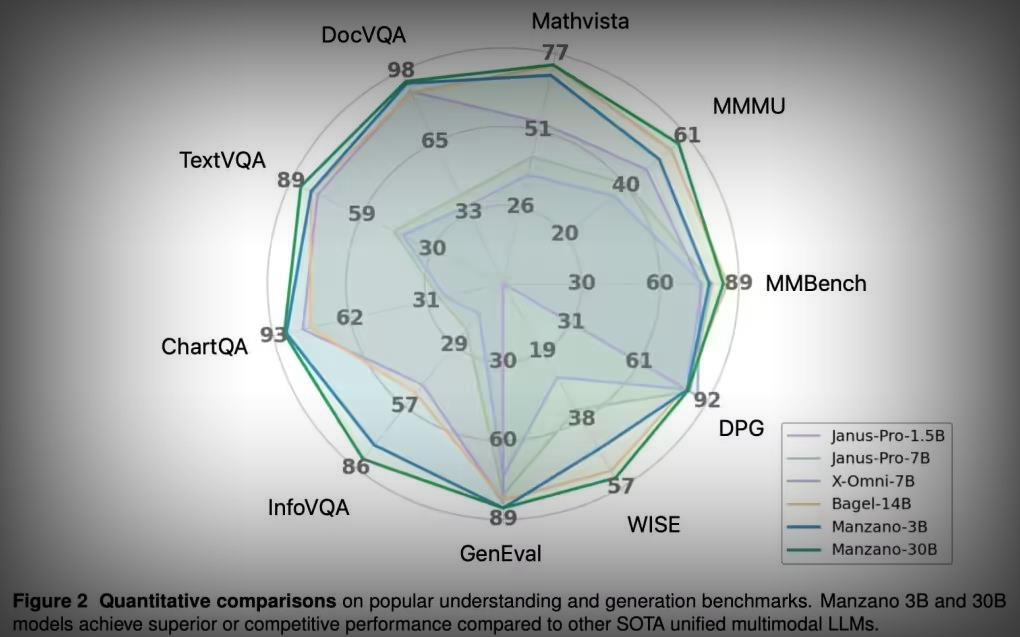
这种设计使得Manzano不仅能准确理解图像内容,还能根据复杂的文本指令生成高质量图片。在测试中,面对“一只鸟在大象下方飞翔”等反直觉指令,其逻辑准确性与GPT-4o等顶尖模型表现相当。此外,它还能处理深度估计、风格迁移等进阶任务。
研究团队验证了从3亿到300亿参数的不同版本,证实该架构具备良好的扩展性。尽管Manzano目前仍处于研究阶段,尚未集成至具体产品中,但业界普遍认为,这项技术未来很可能被应用于“图乐园”等功能,为用户带来更智能的图像编辑与生成体验,从而增强苹果在端侧AI领域的综合竞争力。
原创文章,作者:柠萌,如若转载,请注明出处:https://www.kejixun.co/article/743720.html