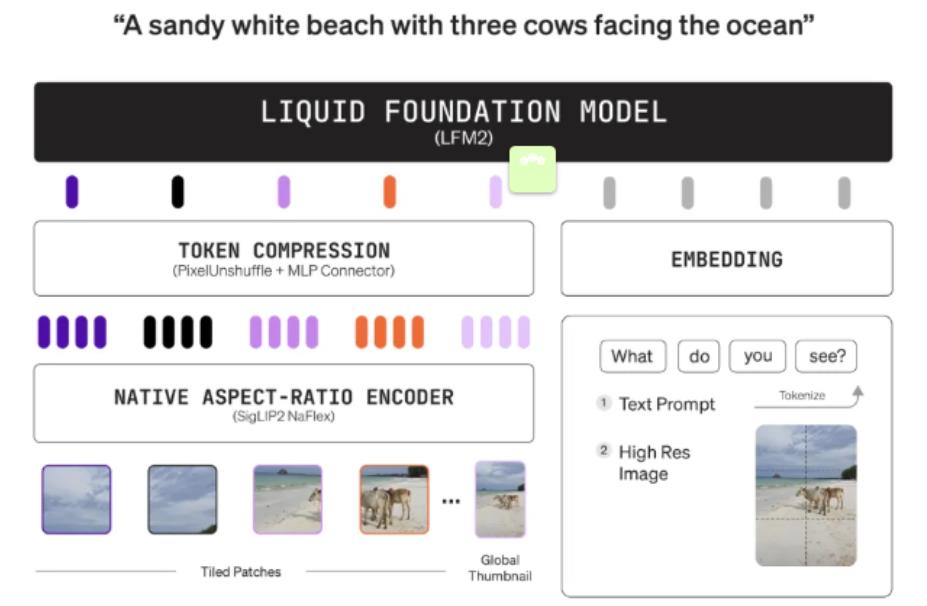
人工智能公司Liquid AI近日正式推出LFM2-VL系列视觉语言基础模型,该系列专为低延迟和设备端部署优化,标志着多模态AI在移动和边缘计算领域取得重要突破。新发布的LFM2-VL包含450M和1.6B两个参数版本,在保持竞争力的同时,将GPU推理速度提升至现有模型的两倍。
LFM2-VL采用创新的模块化架构,结合语言模型主干、视觉编码器和多模态投影器,运用”像素解混”技术动态减少图像标记数量。这一设计使模型能够以原始分辨率处理图像,最高支持512×512像素,较大图像会被智能分割为多个补丁处理。1.6B版本还特别添加了全图缩略图编码功能,确保全局上下文理解能力。
在实际应用中,LFM2-VL展现出出色的灵活性,用户可根据设备性能和应用需求动态调整速度与质量的平衡。在公开基准测试中,其表现与InternVL3、SmolVLM2等大型模型相当,但内存占用更小、处理速度更快。两种模型均已开放权重,开发者可通过Hugging Face获取,商业用户则需联系Liquid AI获取许可证。
这款新模型的推出,将为机器人、物联网、智能摄像头和移动助手等应用提供强大支持,推动设备端多模态AI的普及,减少对云端计算的依赖。
原创文章,作者:聆听,如若转载,请注明出处:https://www.kejixun.co/article/731644.html