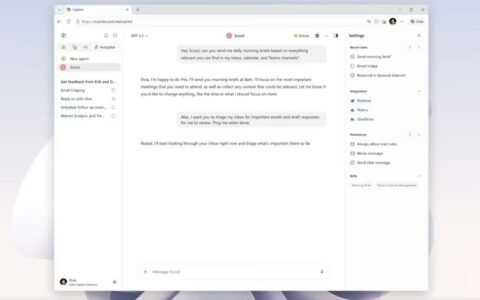
当地时间周四,微软人工智能部门正式发布首批两款自研AI模型——MAI-Voice-1语音模型与MAI-1-preview通用模型,标志着其在AI领域的技术自主化迈出关键一步。据微软介绍,MAI-Voice-1仅需单块GPU即可在1秒内生成1分钟音频,目前已应用于“Copilot Daily”功能中,通过AI主持人播报新闻并生成播客式对话内容。普通用户可通过Copilot Labs平台体验该模型,自定义音色与说话风格,实现高度个性化的语音交互。
同步推出的MAI-1-preview模型则聚焦文本场景,其训练过程动用约1.5万块英伟达H100 GPU,专为特定需求用户设计,具备精准遵循指令的能力,可为日常咨询提供实用回应。微软AI负责人穆斯塔法·苏莱曼此前强调,公司研发方向以消费者体验为核心,依托海量用户数据优化模型,而非优先服务企业级场景。值得注意的是,该模型计划逐步替代Copilot当前对OpenAI模型的依赖,目前已在AI基准测试平台LMAarena展开公开测试。
微软在官方博客中透露了更宏大的技术布局:未来将通过整合多领域专业模型释放更大价值。这一战略既体现了对自研技术的信心,也暗示其可能减少对外部供应商的依赖,进一步强化AI生态的自主可控性。
原创文章,作者:Microsoft,如若转载,请注明出处:https://www.kejixun.co/article/732359.html