PostgreSQL 的每一次版本迭代都为开发者和企业带来令人期待的技术突破。从去年发布的 PG 18 到即将到来的 PG 19,新特性层出不穷——异步 I/O 让云上性能飞跃,内核级 REPACK 解决表膨胀痛点,图查询能力为 AI 时代铺路。但面对如此多的更新,哪些特性真正值得关注?企业什么时候该升级?如何参与到这个充满活力的开源社区?
「YOLANDA 科技见闻」独家专访 HOW 2026(开源生态大会暨 PostgreSQL 高峰论坛)三位深耕 PG 多年的技术专家,IvorySQL专家顾问委员、PostgreSQL ACED、前阿里云数据库高级专家德哥,云和恩墨高级数据库技术顾问、IvorySQL 专家顾问委员彭冲,PostgreSQL ACE、PG分会西安用户组主席、公众号【PostgreSQL 运维之道】主理人杨向博,墨创数迹创始人汪丹(Yolanda)主持,共同为你解读 PG 18 的“真香”时刻,前瞻 PG 19 的重磅更新,并分享实用的企业升级策略与社区贡献指南。
划重点:
1.PG 的每一次大版本发布,都是令人惊喜的。它不是简单的修修补补,而是有很多亮眼的新特性,真实解决了很多痛点问题。
2.PG 的进化不是激进的,而是务实的。社区的严苛性保证了稳定性,插件生态验证了需求,内核化完成了收敛。这是 PG 独特的进化路径。
3.PG 不会为了追求新特性而牺牲稳定性,也不会因为保守而拒绝变化。其丰富插件的可扩展性优势,让很多东西可以像搭积木一样实现。
4.从 PG 18 的异步 I/O 支持、统计信息保留,到 PG 19 的 REPACK 内核化、图查询引入,我们看到了未来数据库的更多可能性。
5.企业什么时候应该升级新版本?没有最好的版本,只有最合适的版本。不为升级而升级,只为解决真问题。
6.PG 社区开放包容,社区贡献没有标准答案。从报 Bug 到写插件,从文章分享到内核提交,每一个声音都能成为PG进化的一部分。从小处着手,向内核生长。
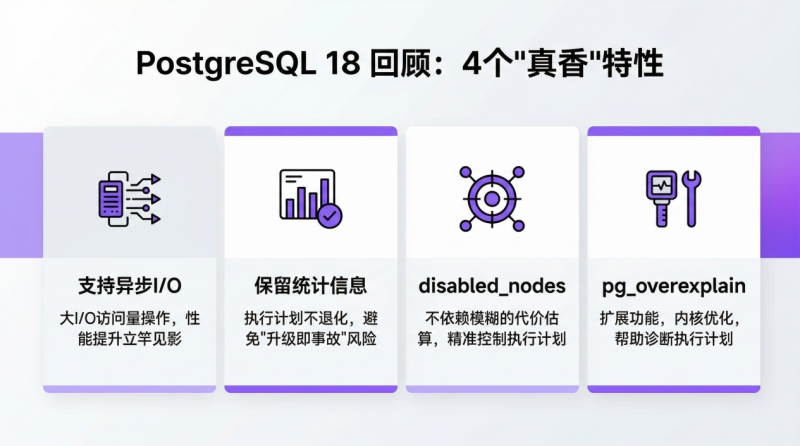
PostgreSQL 18 回顾:4 个“真香”特性
01 支持异步I/O
让德哥觉得“真香”的第一个能力是 PG 18 支持了异步I/O。
现在很多数据库是跑在云上的,云上数据库和线下部署完全是两回事。在本地部署中,数据库直接访问 SSD,I/O 延迟通常在微秒级别。但云上存储会用云盘,云盘底层要通过网络去访问,网络延迟相较于本地部署会高很多。像创建索引、垃圾回收、大表扫描、分析型查询等大 I/O 访问量操作,在 PG 18 之前都使用同步 I/O,数据库进程的大量时间都耗费在网络等待上。PG 18 支持异步 I/O 子系统改变了这个局面,这些大 I/O 访问操作的性能提升立竿见影。
02 保留统计信息
德哥分享的第二个特性和大版本升级有关,可能应用不多,但非常有价值,比如云厂商就会比较激进地提供大版本升级能力。一般来说,大版本升级有两种方式,一种是通过逻辑复制,复制后做切换,不过这种方式有比较严苛的适应场景,要求所有表都要有主键,同步过程中一些不可抗因素也会导致切换后数据不一致。
另外一种是通过 pg_upgrade 直接导出元数据,然后在大版本上面导入新的元数据,这种方式被诟病的地方就是统计信息导不过去,如果升级之后立马开放给用户使用,执行计划就可能不准确。特别是如果遇到业务高峰,或者有一些乱查询,由于没有统计信息往往导致执行计划不准,这种请求多起来的话,很可能带来雪崩效应。PG 18 引入了保留统计信息的能力,彻底解决了这个问题。执行计划不会因为升级而退化,避免了“升级即事故”的风险,这对于无法承受长时间维护窗口的企业级应用来说,是一个质的飞跃。
03 disabled_nodes,精准控制执行计划
向博分享了一个可能会被大家忽略掉、但站在 DBA 角度看非常有用的特性。具体来说,就是 SQL 执行计划会跑偏,这是一个让 DBA 很头疼的问题。怎么办呢?对于一些可以改 SQL 的业务来说,可以走逻辑优化的路径。但对于很多 SaaS 业务,定制化 SQL 改不了,一般就用 hint 提示的手段去做执行计划的修正。
可能会遇到这样的场景:当你指定一个表走更优的索引时,有时会发现它不但没走索引,反而走了顺序扫描。这个路径是怎么被选出来的?PG 17 及以前版本通过disable_cost给一个路径的启动代价加上一个 100 亿的常量值,以此来干预路径选择,方式“粗暴且不优雅”,当多个路径都被加上这个巨大的常量后,原本差距明显的路径可能只相差 1%,它们之间的相对差异反而变得模糊,可能导致干预失效,最终选错了路径。
PG 18 完全去掉了disable_cost这个历史包袱,把它转化成disabled_nodes,一个 int 值,默认为 0,当你禁用一个设置时,对应路径的 node 值加 1,并且这个值会层层向上传递。这样,就可以精确地比较不同路径的干预程度,而不是依赖模糊的代价估算,能更精准地控制执行计划。
04 pg_overexplain,诊断执行计划
彭冲补充了一个和执行计划相关的特性,这是 PG 18 引入的一个扩展功能,pg_overexplain,以一种更结构化、更精准的方式,输出深藏在内核数据结构中的信息,用来深度剖析优化器的内部决策过程,做一些内核相关的优化,可以帮助诊断执行计划。
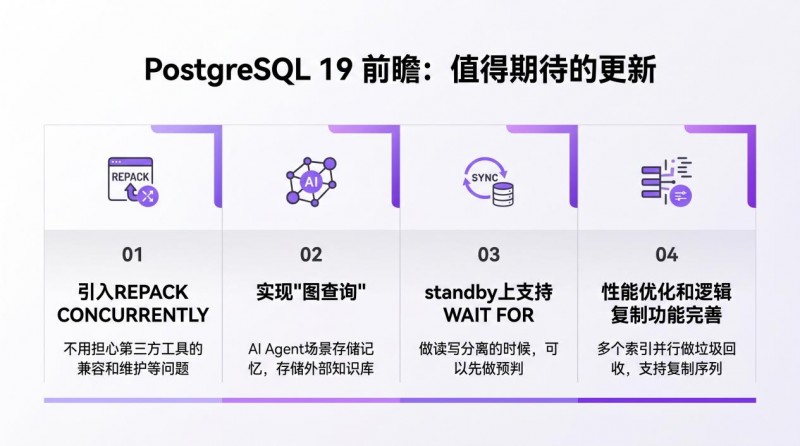
PostgreSQL 19 前瞻:值得期待的更新
对于 PG19,德哥一直在跟进它的 Git 提交记录,从 2600 多个 Commits 中筛选了好几道,最开始筛出来 100 多个,觉得都特别有价值,德哥重点分享了几个对他来说冲击比较大的新能力。
01 引入REPACK CONCURRENTLY
使用 PG 的一个痛点就是它的事务 ID 只有 32 位,容易用完,所以必须不断地做“冻结”操作。另外就是 PG 的存储引擎,没有 Undo 回滚段,所有垃圾都放在数据文件里,和正常的数据放在一起,就要不断地做垃圾回收。一旦表膨胀了就会很麻烦,特别是在云服务里,存储都得额外算钱,那每月的账单就要滴血,压缩膨胀空间就很关键。怎么办?原来是通过第三方的pg_repack插件来解决,PG 19 把REPACK CONCURRENTLY做到内核里来了。以后我们就可以很放心地使用REPACK CONCURRENTLY了,不用担心第三方工具的兼容和维护等问题,这是一个极大的利好。
02 实现“图查询”
AI 时代,图查询是一个非常重要的特性。比如我们使用 Agent 的时候,使用越多,它堆积的记忆就越多,包括 Agent 去连接各种外部知识库,这些数据也非常复杂。以前 PG 只能提供一些向量搜索、关键词搜索、全文检索,但实际上来看,知识很多时候是树状结构的,也就是图结构。这时候,很多企业可能会选择额外再搭一套图数据库,就会导致一些数据可能是重复的,浪费企业资源。
PG 19 终于把图查询的功能引进来了,在 AI 场景存储记忆、存储外部知识库,这是一个很有必要的、很高级功能。德哥相信,将来的 AI 应用在使用数据库的时候,都可能把这块功能给用起来。
03 standby上支持 WAIT FOR
比如读写分离场景,当业务要求只读查询和之前写入变更的事务之间必须有一个前后顺序,很多时候我们的查询不能发到只读库,因为不知道只读库回放到什么时候了,有没有把之前的修改回放过去,这种情况下,压力还是得压到主节点。
PG 19 有了 WAIT FOR,当我们做读写分离的时候,可以先做预判,判断一个只读节点是否已经同步了之前写入的事务,检查回放进度 LSN,回放到了,就把后面的请求转发给这些只读节点。这是一个很好的特性,值得我们持续关注后续应用。
04 一些“补丁”能力:VACUUM性能优化和逻辑复制功能完善
当一个表有很多索引时,特别是大表,以前每个索引是顺序地(一个一个)做垃圾回收,PG 19 的autovacuum可以并行地对多个索引同时做垃圾回收,这能大大缩短垃圾回收的总时间。
对于逻辑复制功能,不支持复制序列(SEQUENCE),在 PG 19 里这个功能也补充上了。
企业升级策略:痛点驱动升级
PG 19 要来了,不过很多用户使用比较多的版本还是 PG16、PG17,大家对于新版本用得还不多,毕竟在生产环境下需要一个小心谨慎的态度。具体什么时候应该升级?怎么用好新版本的能力?三位专家也根据具体场景给出了一些升级建议。
场景 1:云部署 + 大 I/O 操作
·如果你的数据库跑在云盘上,且有频繁的索引创建、垃圾回收、大表扫描
·建议升级 PG 18,异步 I/O 带来巨大的性能提升
场景 2:表膨胀困扰
·如果你的表经常膨胀,存储成本高,查询性能下降
·建议等待 PG 19,内核级 REPACK 更稳定,更放心
场景 3:信创 + 跨 CPU 架构
·如果你有信创需求,需要在 ARM 和 x86 之间做流复制或迁移
·建议升级 PG 17/18,提供内置的字符比较、排序比较,兼容性处理
场景 4: AI 应用(Agent) + 知识图谱
·如果你在构建 AI Agent,需要存储记忆、知识图谱;需要单独维护图数据库,数据同步复杂
·建议等待 PG 19,图查询是标配能力,原生支持图查询,统一数据平面
具体场景挑战很多,比如逻辑复制引起磁盘堆积问题、数据库拷贝难题、外部表安全问题等等,根据自身业务的痛点和 PG 版本能力做匹配,是一种可靠的判断逻辑。
另外,对于升级原则,德哥还分享了一个他的思路。对于相对传统一点的企业,如果业务迭代速度或者变化节奏不是特别快,不用太着急去升级,遇到特别大的痛点,新版本能很好解决,这时候再考虑升级。对于业务本身变化极快的企业,可以考虑更快地使用新版本带来的新特性,比如 PG 19 的图查询能力,可以给 AI Agent 相关的业务带来极大助力,帮助提升应用的竞争力,那就可以偏激进一点去使用新版本。
多元的社区贡献指南:成长于社区,贡献于社区
PG 社区对新人非常友好,包容性强,那如何更好地在社区做共享?怎样参与到 PG 下一个版本的新特性开发中?三位深耕于 PG 社区多年的专家分享了他们的经验与建议。
1.从报 Bug 开始:从使用者的角度,如果发现了 Bug,直接在 PG 官网按照模板提交。重要提醒:一定要写清楚信息,包括详细的环境信息(比如版本号、操作系统、硬件配置),这个问题你是怎么复现的等等。如果只是填了一段报错上去,沟通效率会比较低。
2.写插件:一上来就参加内核贡献,门槛还是稍微高了一点。PG 的插件生态非常广,可以从插件入手。有什么好点子,或者在使用过程中遇到了一些问题,也许写插件就能解决,那就先快速写出来,也可以利用好 AI 工具来帮助实现。比如可以写一些巡检脚本,或者写一些 Skills。等插件成熟了,社区可能会考虑将其引入内核。
3.写文章做分享:写文章也是贡献,比如可以从实际的案例出发,分享故障解决经验、自己的思考和心得等等。
4.内核贡献三步法:第一步,观察社区的沟通方式。先去邮件列表里边看大家是怎样交流沟通的,了解 Bug List,观察代码风格,把这个流程或者大家的习惯梳理清楚。第二步,从小问题入手。可以从社区现有的 Bug List 里找痛点,先去解决好一个具体的小问题。第三步,大胆提交,接受反馈。PG 社区对新手特别友好,大佬们非常包容,不过 PG 的代码审查很严苛,要有心理准备,被拒绝是正常的,每一次反馈都是学习机会。
结语:PostgreSQL 的进化哲学
从 PG 18 到 PG 19,PostgreSQL 的每一个特性都经历了反复讨论与充分验证。PG 不追求激进的创新,而是在稳定性的基石上,稳步演进至最佳实践。这种务实的进化哲学,或许正是 AI 时代我们真正需要的。PG 19 将成为一个新的起点,未来,AI 时代下数据库的更多可能性、更令人激动的篇章,值得共同期待。
4 月 27 – 28 日,1 场主论坛+12 大主题分论坛,覆盖数据库技术的关键路径与前沿方向,一次性展开 PostgreSQL 在当下与未来的完整技术版图。欢迎报名参加,我们济南见。
原创文章,作者:聆听,如若转载,请注明出处:https://www.kejixun.co/article/750616.html