9月23日,阿里云今日发布并开源了全新的 Qwen3-Omni、Qwen3-TTS,以及对标谷歌 Nano Banana 图像编辑工具的 Qwen-Image-Edit-2509。
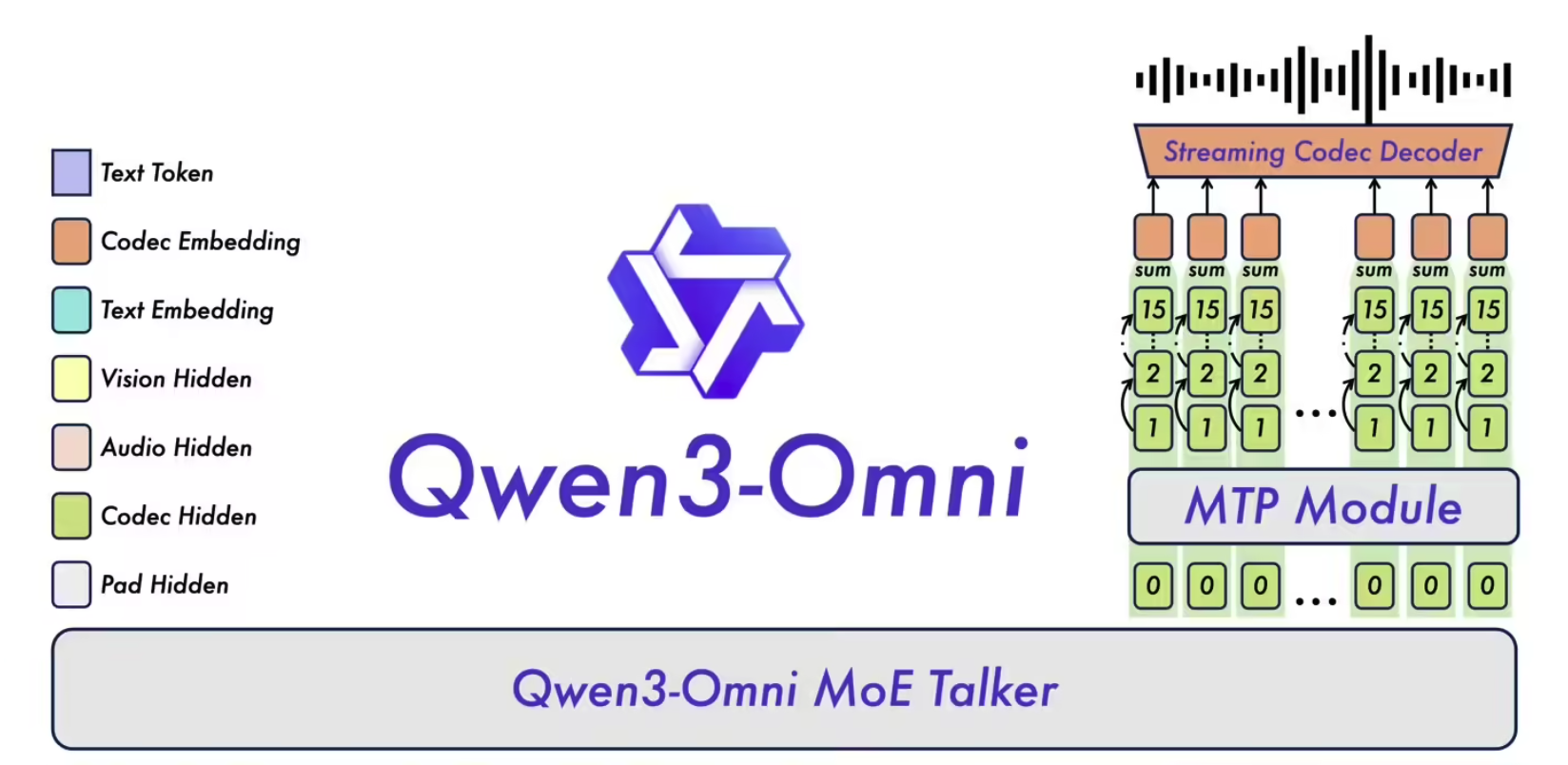
Qwen3-Omni 是业界首个原生端到端全模态 AI 模型,能够处理文本、图像、音频和视频多种类型的输入,并可通过文本与自然语音实时流式输出结果,解决了长期以来多模态模型需要在不同能力之间进行权衡取舍的难题。
Qwen3-Omni 是原生端到端的多语言全模态基础模型,其核心特性主要包括:
跨模态最先进表现:通过早期以文本为核心的预训练和混合多模态训练,模型具备原生多模态能力。在实现强大音频与音视频性能的同时,单模态的文本与图像效果保持不降。在 36 项音频 / 视频基准测试中,22 项达到了最新水平,其中 32 项在开源范围内处于领先;在自动语音识别(ASR)、音频理解与语音对话方面表现可与 Gemini 2.5 Pro 相当。
多语言:支持 119 种文本语言、19 种语音输入语言以及 10 种语音输出语言。
语音输入语言:英语、中文、韩语、日语、德语、俄语、意大利语、法语、西班牙语、葡萄牙语、马来语、荷兰语、印尼语、土耳其语、越南语、粤语、阿拉伯语、乌尔都语。
语音输出语言:英语、中文、法语、德语、俄语、意大利语、西班牙语、葡萄牙语、日语、韩语。
创新架构:基于 MoE(专家混合)的“思考者–表达者”设计,并结合 AuT 预训练以获得强大的通用表征能力,同时采用多码本设计以将延迟降至最低。
实时音频 / 视频交互:低延迟流式交互,支持自然的轮流对话和即时的文本或语音响应。
灵活控制:可通过系统提示词自定义行为,实现细粒度控制与轻松适配。
精细音频描述: Qwen3-Omni-30B-A3B-Captioner 已开源,这是一个通用型、细节丰富、低幻觉率的音频描述模型,填补了开源社区在该领域的空白。
据报道,TTS 即文本转语音,阿里云此次发布的 TTS 支持 17 种音色选择,每一种音色均支持 10 种语言。其中不仅包含多国语言,有:普通话、英语、法语、德语、俄语、意大利语、西班牙语、葡萄牙语、日语、韩语;还支持了更多中国方言:闽南语、吴语、粤语、四川话、北京话、南京话、天津话和陕西话。
此外,Qwen3-TTS-Flash 在多项评估基准上均取得了 SoTA 的表现,超越 SeedTTS、MiniMax、GPT-4o-Audio-Preview、Elevenlabs,特别是在语音稳定性和音色相似度。
原创文章,作者:科技观察者,如若转载,请注明出处:https://www.kejixun.co/article/734502.html