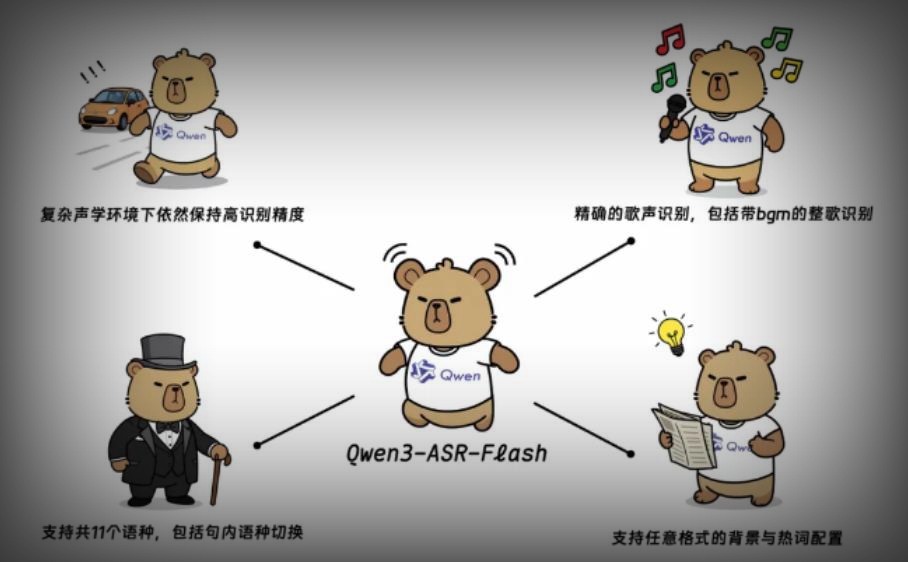
在全球语音识别技术快速发展的背景下,通义千问今日正式发布其最新语音识别模型Qwen3-ASR-Flash。该模型基于Qwen3基座模型,经过海量多模态数据及数千万小时自动语音识别(ASR)数据训练,旨在为用户提供高精度、高鲁棒性的语音识别解决方案。
Qwen3-ASR-Flash的核心特性包括领先的识别准确率和出色的歌声识别能力。在多个中英文及多语种基准测试中,该模型表现优异,尤其在歌唱识别方面,实测错误率低于8%。这意味着无论是清唱还是伴随背景音乐的整歌,Qwen3-ASR-Flash都能有效识别并转录,为音乐爱好者提供了极大便利。
另一个显著特点是其定制化识别能力。用户可以以任意格式提供文本上下文,模型能够智能识别并匹配命名实体和关键术语,输出个性化的识别结果。这一功能使Qwen3-ASR-Flash在处理复杂语境时更具灵活性和适应性,满足不同场景下的专业需求。
此外,该模型支持多达11种语言及多种方言和口音,包括普通话、四川话、粤语等主要方言,以及英式、美式英语、法语、德语、俄语、意大利语、西班牙语、日语、韩语和阿拉伯语等。广泛的语种支持使其能够满足全球不同地域和语言使用者的需求,实现精准转录。
Qwen3-ASR-Flash还具备强大的鲁棒性,在长难句、语言切换和复杂声学环境中保持高准确率,有效过滤静音和背景噪声,确保用户获得最佳体验。目前,用户可通过ModelScope、HuggingFace和阿里云百炼API等平台体验该模型。
原创文章,作者:好奇宝宝,如若转载,请注明出处:https://www.kejixun.co/article/733301.html