据悉,昇思MindSpore开源社区将于 2025 年 12 月 25日在杭州举办昇思人工智能框架峰会。本次峰会的昇思人工智能框架技术发展与行业实践论坛将讨论到昇思MindSpore大模型套件技术进展与实践,MindSpore Transformers SIG的核心贡献者将在昇思开发者动手实践workshop设立开发者动手实践体验,带领开发者体验使用昇思MindSpore Transformers大模型套件实现高效训推。本文对MindSpore Transformers套件的架构升级进行了深入解读,揭示其如何实现迁移效率的提升。
为应对大模型开发中生态割裂、迁移复杂与并行编程难度高的挑战,MindSpore Transformers套件完成Mcore架构重大升级。本次升级通过极简化的模型迁移开发范式与原生支持Hugging Face生态的零修改复用两大核心技术革新,显著降低大模型在昇腾平台上的开发与部署门槛,实现从开源模型到高效训练、推理的端到端敏捷链路。
模型迁移开发范式革新——从“重复造轮子”到“配置化搭建复用”
传统模型迁移是一项繁重且低效的工作:开发者不仅需要花费数周时间从零开始重写模型的配置、核心代码和分词器,还要在不同但结构相似的模型间进行大量的重复实现,导致“重复造轮子”。此外,训练与推理接口的高度耦合使得代码维护困难,针对某个主力模型的深度优化也难以被其他模型复用,整体迭代和共享效率低下。
如今,全新的MCore架构通过深度拥抱开源生态与模块化设计,彻底重构了这一流程(如图1)。我们建立了模板化、声明式的模型开发范式,将开发重心从编写大量代码转向灵活的配置定义;并对Transformer核心组件进行了标准化接口抽象,确保各项高性能优化能力能在所有模型中沉淀和共享;其次,实现了对Hugging Face生态的零修改复用,可以直接使用其模型配置与分词器。最终,用户的主要工作量被简化为轻量的配置适配,从而将模型迁移的整体工作量降低了90%,成功实现了从“周级”到“天级”的敏捷迁移。
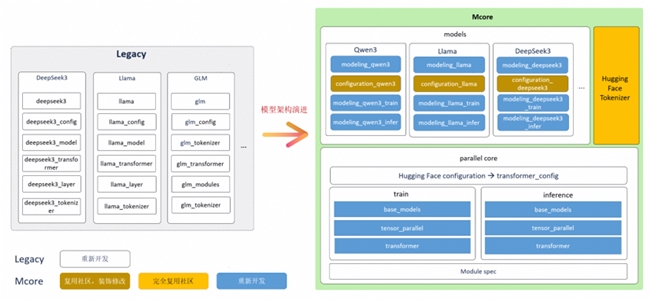
图1 Mcore架构升级
具体而言,基于代理模式的设计思想,我们底层定义了GPTModel通用预训练模型基类,封装了绝大多数同构模型(如Qwen、DeepSeek、Llama)的共性结构。外层以代理方式实现Hugging Face式的表层实现(见图2),使得使用方式和Hugging Face社区一致,但降低了维护成本。
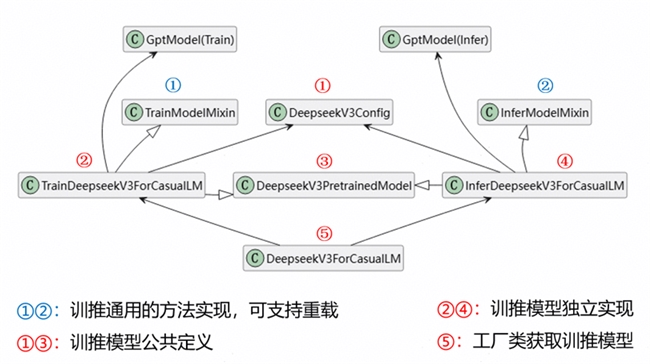
图2 基于代理模式的Hugging Face-Style模型实现
如图2所示,针对训练和推理两大场景,对于每个模型我们实现了训练、推理两个模型接口,并在实际任务中根据训练或推理场景,通过工厂类来获取训练或推理的模型实例。同时我们了训练和推理两套高阶transformer接口,针对于训练和推理所需的并行优化与底层算子的不同。提供的接口包含Attention、MLP、Embedding等等的Transformer典型结构(如图3),封装了高阶的并行能力,用户只需配置每种并行模式的切分数量,而无需关注接口中每个算子的切分逻辑。并统一使用了Mint高精度算子,做到了接口级的精度对齐。

图3 Transformer相关高阶并行接口
基于此,我们引入了ModuleSpec声明式配置机制。开发者无需再深入底层,硬编码式地逐行编写或修改模型的前向传播代码。而是可以像搭积木一样,通过简洁的ModuleSpec接口,声明式地指定:“在这里使用Multi-Head Attention算法”、“在那里采用SwiGLU激活的MLP”。系统便会自动将这些标准化、模块化的组件,按照基类定义的模板组装成完整的模型。这种机制不仅让模型搭建变得灵活高效,便于快速实验不同组件组合,其清晰的模块边界更使得对Attention、Norm等单一模块进行独立的精度对齐与性能调优成为可能,大幅提升了开发调试的效率。
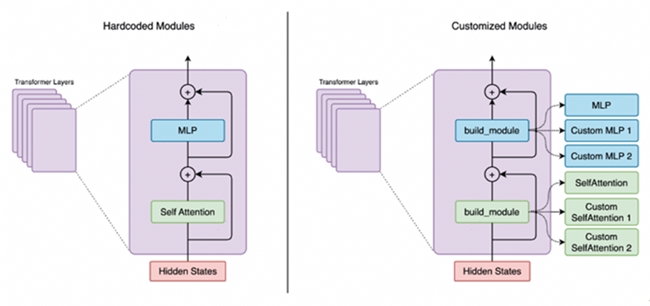
图4 基于ModuleSpec灵活搭建模型
无缝对接Hugging Face生态——零修改复用模型配置与权重
Mcore架构设计的原则之一是生态友好,核心目标是与主流开源社区“说同一种语言”,实现Hugging Face生态的零修改、开箱即用,将开发者的适配成本降至最低。
Mcore架构实现了对Hugging Face模型仓库(Model Hub)的本地读取,包括对模型配置、模型权重的读取与自动转换,以及Tokenizer分词器的复用,用户仅需在Yaml配置文件中配置模型仓库的本地地址,即可加载模型配置、权重和Tokenizer分词器。

• 配置自动转换:通过复用Hugging Face模型的配置类configuration_model.py,用户可直接使用来自Hugging Face的config.json配置文件。Mcore通过配置装饰器机制,在运行时补全MindSpore Transformers的特有参数,并删除无关配置参数,最后自动转换成统一的TransformerConfig,以实例化模型结构(如图5)。
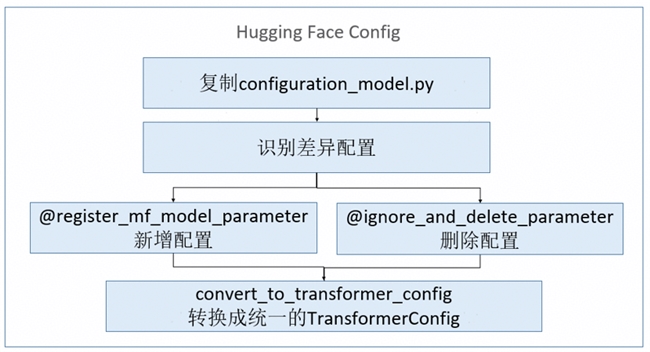
图5 适配Hugging Face配置
• 权重自动转换:通过架构内置的自动化权重名称映射系统,直接加载Hugging Face标准的safetensors权重文件。对于新增模型,仅需实现权重参数名转换的映射表,即可在加载权重时自动将Hugging Face社区模型的参数名称映射至Mcore的内部结构。用户无需关心权重的分布式切分,训练和推理场景下权重均可进行自动切分并加载。
图6 适配Hugging Face权重

• Tokenizer分词器复用:MindSpore Transformers现已接入Hugging Face Tokenizer,通过读取模型仓库中的词表文件和分词器配置,进行实例化并用于数据编解码。
Mcore架构模型迁移流程解读——模型三步标准化迁移
基于Mcore架构迁移一个全新的模型,开发者通常只需准备三类核心文件:
1、模型配置类文件:继承Hugging Face原配置,通过装饰器补全所需配置,忽略无关配置。
2、模型类文件:继承自GPTModel等基类,通常仅需百行代码定义特殊结构。
3、权重参数映射文件:声明Hugging Face与Mcore间的参数名对应关系。
以Qwen3为例,主要包含以下几类核心文件:
• 模型配置类文件:configuration_qwen3.py
定义了Qwen3的模型配置。直接复用了Hugging Face的配置定义,并加入了装饰器声明需要补全和忽略的配置项。
以下代码片段展示了装饰器部分:

• 模型类文件:modeling_qwen3.py、modeling_qwen3_infer.py、model_qwen3_train.py
分别定义了Qwen3的模型工厂类、推理模型和训练模型。推理和训练模型使用GPTModel抽象接口和ModuleSpec机制搭建模型结构。
以下代码片段展示了Qwen3训练模型的构造声明部分:

• 权重参数映射文件:utils.py
定义了Qwen3权重参数的映射表,映射Hugging Face模型参数和MindSpore Tranformers模型参数。
以下代码片段展示了Qwen3权重参数的映射表:

Mcore架构的新迁移模式将模型迁移的开发工作量降低了一个数量级。以迁移DeepSeek-V3为例,与原有架构的代码量对比如下(单位:代码行数loc):

“一键”启动Hugging Face模型微调与推理
开发完成上面章节介绍的三类文件后,可以通过MindSpore Transformers的通用流程,读取Hugging Face下载的模型仓库,“一键”快速拉起微调和推理任务。下面以Qwen3-0.6B为例,展示了拉起微调和推理的具体步骤:
1、前置准备
请参考安装指南(https://www.mindspore.cn/mindformers/docs/zh-CN/r1.7.0/installation.html)准备MindSpore Transformers的运行环境,选择1.7.0版本的MindSpore Transformers,安装配套版本的依赖软件。
从Hugging Face下载Qwen3-0.6B(https://huggingface.co/Qwen/Qwen3-0.6B/tree/main)仓库至本地。
2、启动微调任务
执行以下命令启动微调任务:


上述命令执行完毕后,多卡训练任务将在后台执行,过程日志保存在./output/msrun_log下,使用以下命令可实时查看训练状态:

更多训练的相关说明请参考训练指南(https://www.mindspore.cn/mindformers/docs/zh-CN/master/guide/llm_training.html)。
3、启动推理任务
准备推理任务的配置文件predict_qwen3.yaml。执行以下命令启动单卡推理,支持在命令参数中直接修改yaml文件中的配置。其中设置pretrained_model_dir为步骤1中下载的Qwen3-0.6B仓库地址。

上述命令执行完毕后,日志会打印在控制台。出现如下结果,证明推理成功。

更多推理的相关说明请参考推理指南(https://www.mindspore.cn/mindformers/docs/zh-CN/r1.7.0/guide/inference.html)。
亦可参考服务化部署指南(https://www.mindspore.cn/mindformers/docs/zh-CN/r1.7.0/guide/deployment.html)进行模型部署()。
总结
MindSpore Transformers套件的Mcore架构升级,是一次以开发者效率和生态兼容性为核心的系统性工程。通过实现与Hugging Face的零修改复用,它消除了框架迁移的主要障碍;通过提供极简的ModuleSpec模型搭建机制,它将开发重心从重复编码转向配置化复用搭建,减少85%+迁移工作量;通过提供高阶并行接口,它让大模型训推实现配置化并行和接口级精度对齐。
这套组合方案为企业和研究机构在昇思生态上快速落地、迭代大模型提供了坚实的技术底座,使其能更敏捷地响应技术变化,将资源聚焦于模型创新与应用本身。
本次在杭州举办的昇思人工智能框架峰会,将会邀请思想领袖、专家学者、企业领军人物及明星开发者等产学研用代表,共探技术发展趋势、分享创新成果与实践经验。欢迎各界精英共赴前沿之约,携手打造开放、协同、可持续的人工智能框架新生态!

本文来自投稿,不代表科技讯立场,如若转载,请注明出处:https://www.kejixun.co/article/740884.html